
I’ve been talking to people about OpenShift for a long while now, and one of the biggest issues I’ve seen with customers is that missing bit of glue between the rabid developers throwing together a cutting edge application and the Ops teams deploying it in the Real World (TM).
With the advent of Kubernetes and it’s delightfully cool declarative object model the opportunity to make it easier and, more importantly, consistent has led to the rise of the ArgoCD project, hosted at https://argo-cd.readthedocs.io/en/stable/
I don’t know about you but I have an oddly ordered (cough, OCD) mind; I like things tidy. I’ll spend hours indenting code, making sure comments are verbose (I used to get accused of writing novels of comments) and the like; being honest I like things to be ordered and controlled. And that’s where ArgoCD comes in, in spades.
So, to put it simply, what ArgoCD allows you to do is to group resources, apply resources from a controlled source, and maintain and synchronise those sources automatically. It takes declarative definitions for objects within Kubernetes backed by git controls, applies them appropriately and provides one of the best UIs I’ve seen in a while for managing and observing the process and controls.
Enough praise (I could go on for hours, there’s something brilliant about the application of controls that ArgoCD provides), let’s walk through a basic couple of examples to show you it working in practice. Again, as I’m an OpenShift geek, these examples will be done with the OpenShift GitOps operator.
Basically, what Red Hat have done, as with a lot of the Open Source projects, is to integrate it into the OpenShift ecosystem (the RBAC, monitoring, logging) and provide a seamless experience with the OCP platform. ArgoCD is the same at the core, so these examples should work on a basic Kubernetes system (aside from the addition to the OCP UI example of course).
I’ve also lifted a lot of the basic operations from the fantastic https://github.com/siamaksade/openshift-gitops-getting-started guide; I would wholeheartedly suggest reading it in full after this if you want more of an introduction.
In terms on installation feel free to skip this paragraph, but if you haven’t and want to know how simply log on to an OCP4.x (supported) system (which you can create via https://cloud.redhat.com/openshift) with Cluster Admin rights, install the ‘OpenShift GitOps operator and then go to the ArgoCD route – you’ll need the administration password and that can be obtained by logging onto the Cluster via ‘oc’ and running ‘oc extract secret/openshift-gitops-cluster -n openshift-gitops –to=-‘ which will give you the password you need.
Back up a step – so what is GitOps? Put simply it’s the approach of defining the state of your estate, both configuration of the Clusters and the Applications, in a controlled code way, via a Git repo. Then the Cluster can be brought into a compliant state by applying the configuration, applications can be deployed and kept at a consistent state by applying the latest version of their configuration from the git repo. It also means that an Op can determine the exact state of an application/cluster programmatically, and also perform repeated and consistent installations of cluster state/applications. It’s, well, tidy.
So back to the example – I have setup two ‘pots’ of configuration in a github repo (see https://github.com/utherp0/gitopsdemo1). There are two subdirectories in that repo, one called ‘cluster’ and the other called ‘app’. These are created by me; ArgoCD has the concept of an ‘Application’ which is a group of definitions sourced from the same github repo; in this case I’ll be creating two ‘applications’, the first a couple of Cluster objects and the second an actual application.
The ‘cluster’ subdirectory contains two pieces of YAML – one defines an addition to the OpenShift UI (it basically adds a clickable link/icon to the applications tab in the UI using a console.openshift.io/v1/ConsoleLink object) and the other is a namespace that I want created on my cluster.
For reference the definition for the ConsoleLink looks like this (it’s just a declarative piece of YAML):
apiVersion: console.openshift.io/v1
kind: ConsoleLink
metadata:
name: application-menu-myblog
spec:
href: 'https://devepiphany.org/home/'
location: ApplicationMenu
text: DevEpiphany Blog
applicationMenu:
section: Blogs
imageURL: https://i.ibb.co/pZ0Lxdb/Logo-Red-Hat-Hat-Color-RGB.pngNote that, as expected, there’s nothing ‘ArgoCD’ about these files; they are just definitions of various objects I want in my cluster.
The ‘app’ directory is slightly different; I actually created it for a Red Hat Advanced Cluster Manager demo (ACM takes kustomise manifests as a definition for ‘applications’ that can be deployed cross cluster). ArgoCD works with kustomise – if you have a kustomise manifest in the directory (or sub-directories – ArgoCD can do a recursive dive through the repo if indicated, more in a moment) that will be applied; in the case of this app the manifest defines three components, a deployment, a service and a route. These additional objects are present in the repo subdirectory.
The Deployment defines two replicas and the image to deploy – so the application I want deployed is two Pods containing a pre-built image, a service and a route so the app can be reached from outside of the cluster.
So, having installed ArgoCD (in this case, OpenShift GitOps via Operator) and logging on with the creds I get the following screen:
First thing I’m going to do is add the cluster configs as an app; I click on ‘+New App’ and add the following – the Application Name is ‘clusterconfigs’, the project is ‘default’, I leave the sync policy as ‘Manual’ **, set the source repository to https://github.com/utherp0/gitopsdemo1 with the path set to ‘cluster’.
For the destination I choose the local cluster on which ArgoCD is running (by default this is https://kubernetes.default.svc) and the namespace as ‘default’ within the cluster. I also click ‘Directory Recurse’ (although in this case all the YAML components I want are in the cluster directory).
I then hit create and et voila, we have a managed application within ArgoCD…..
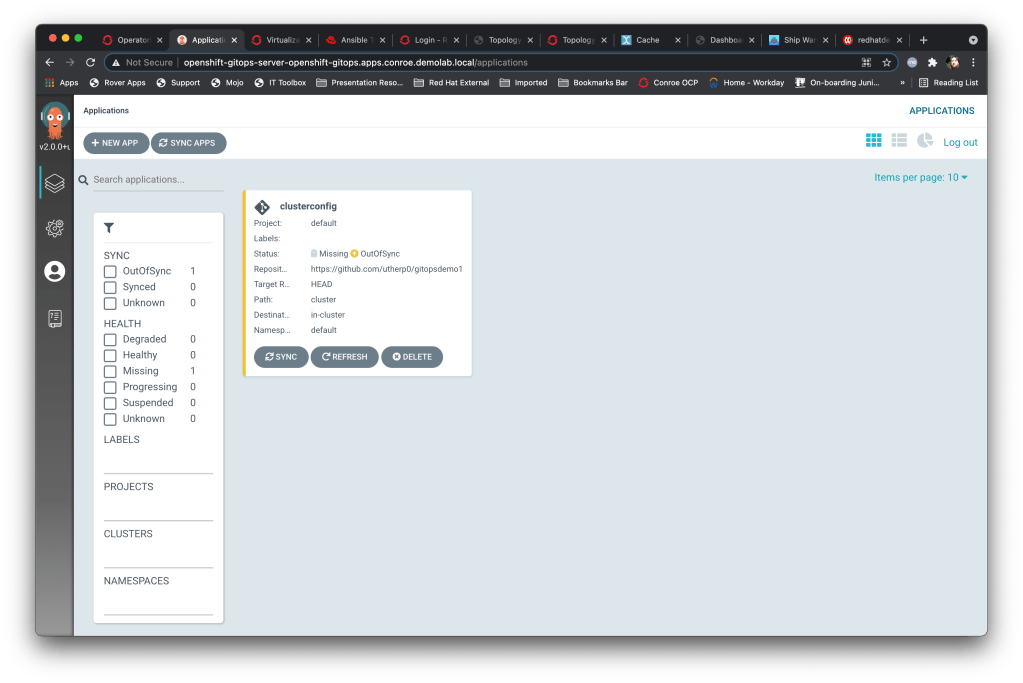
You’ll immediately notice that the status of the app is ‘missing’ and ‘out of sync’ – this is because we chose to do a manual sync, which we haven’t done. So the next thing to do is to sync that application against the git repo, which I do by clicking on the ‘Sync’ button.
This is where it gets nice – shown below is the panel that pops up for synchronising; you’ll notice it already knows the content of the git repo target (by scanning ahead) and shows the files that will be sync. You can choose to remove files here, although that isn’t best practice. So I’ll just hit ‘synchronise’.
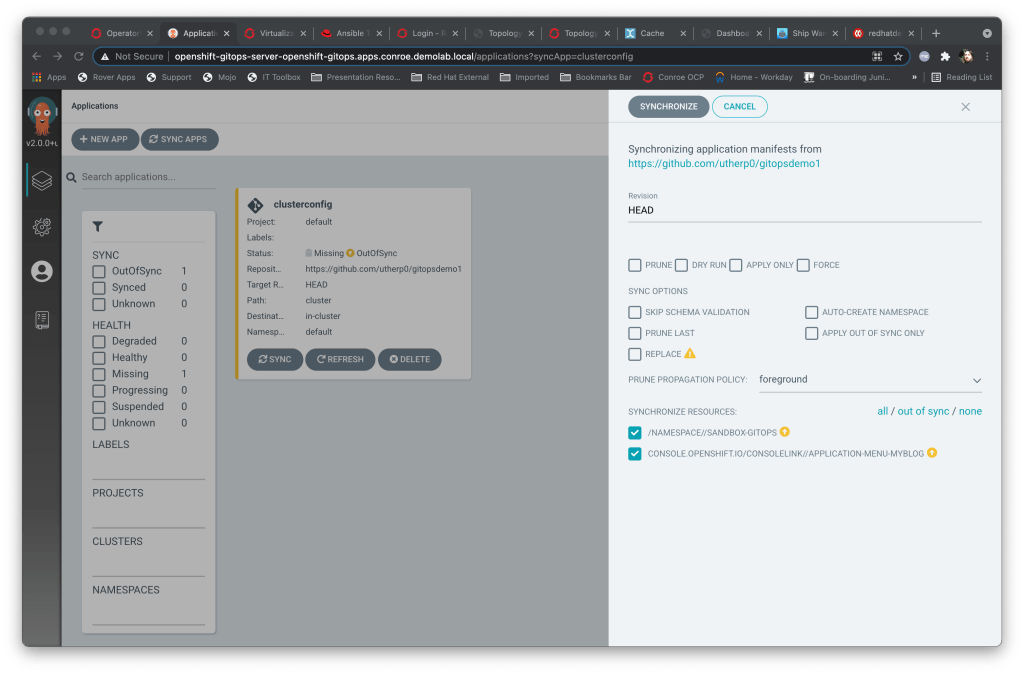
Once I have hit ‘synchronise’ it takes me back to the overview but now my application is rendered thus:

So what has this done? ArgoCD has pulled the files from that target repo and executed them against my cluster. To prove that it has I can go back to my Cluster UI and select the Applications button, which now has the additional entry for this blog added.
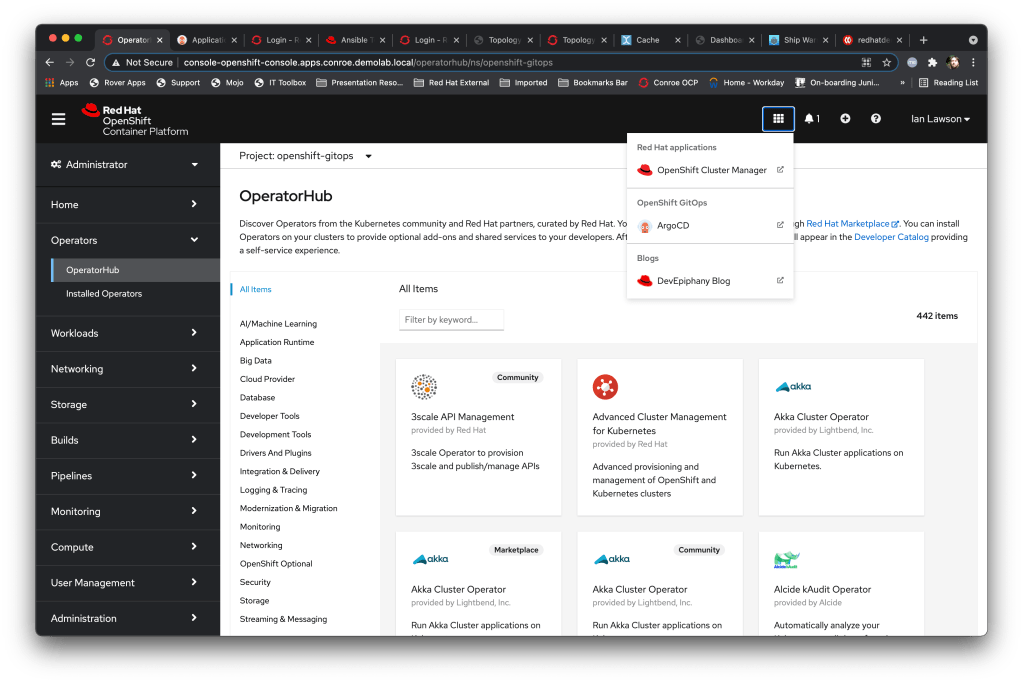
I also created a namespace, my GitOps sandbox for messing around in, and that is visible as well.
oc get projects | grep gitops
openshift-gitops
sandbox-gitops So, I now add another ‘application’ at the ArgoCD side; this time I set it to automatically synchronise and point it at my app directory on the repo that has the kustomise manifest. I also target the namespace I have just got ArgoCD to create, sandbox-gitops.
And then I hit a little snag. The application cannot sync because OpenShift is behaving itself, security-wise; by default the ArgoCD service account is limited to its own namespace. I fix this by adding the ArgoCD service account as an admin user on the namespace I created – I could (and should) have done this by creating a role-binding piece of YAML and adding that to the cluster repo (add to my todo list).
And ooo, I like the UI for this; if I click on the Application in the ArgoCD project viewer it displays exactly what it has synced and created thus:
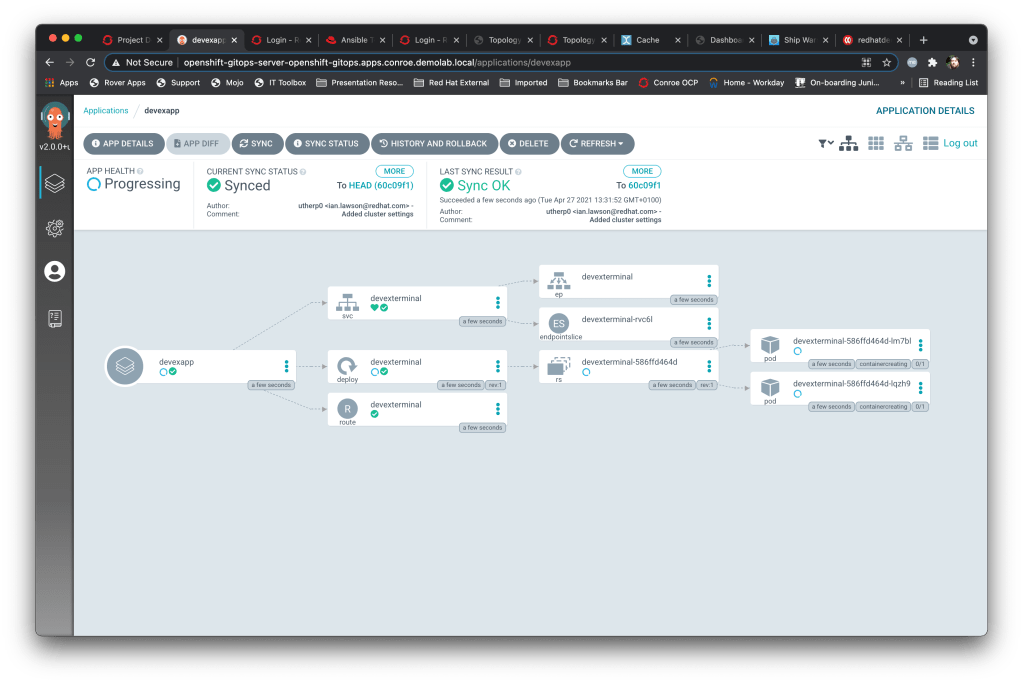
You can see the service, the route and the deployment, which has a replicaset and is running two Pods. It has correctly synced the files from the repo and applied them as required.
I then hopped onto github and manually edited the deployment, setting the replicas to 4. I then popped back to ArgoCD, hit refresh on the ‘devexapp’ and et voila, it had synced my changes and now:
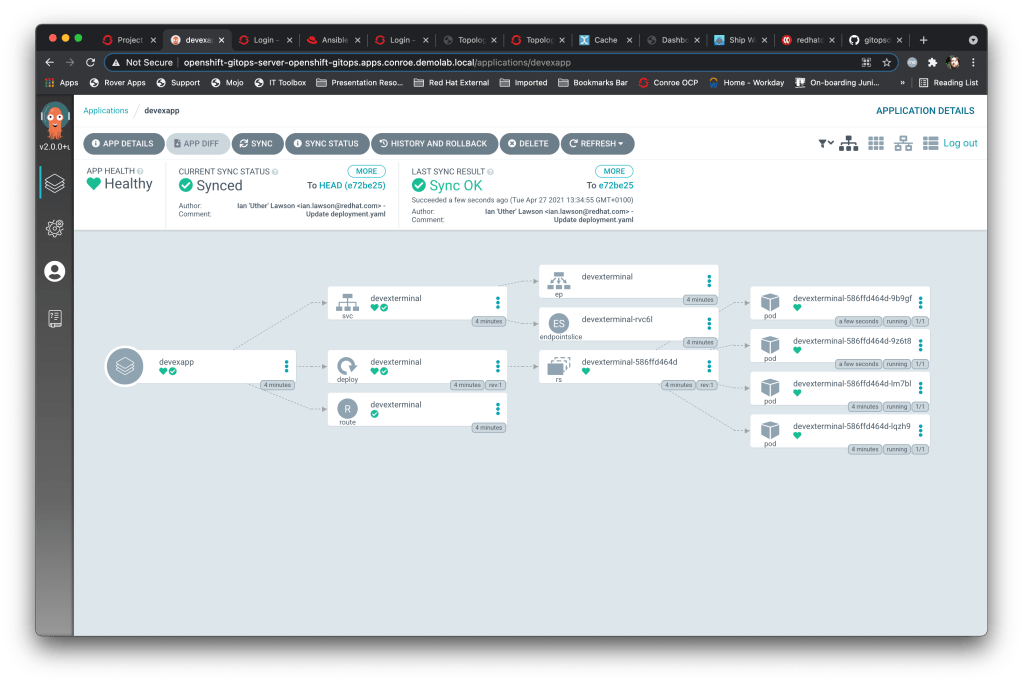
So yeah, a bit of a pithy example but you can see the power of this. My intention is, from now on, to craft kustomise manifests for all my reproducible demos and use ArgoCD internally within my demonstration clusters to set them up and keep them up to date against my git repo.
So that was a lightning fast overview of some of the functionality of ArgoCD from a basic view; now to work on crafting my demos……
