One of the best things about working for a company like Red Hat is that it gives you a chance, if you want it, to get involved with any aspect of the company. I volunteered, this year, to help out with coding the demo for Summit and ended up writing a set of functions, in Quarkus, driven by Cloud Events for processing the game state (for those who missed it we did a retro-styled version of Battleships completely event driven, node.js front end and game server, state update engine in functions and state held in a three cluster geo-replicated instance of Red Hat Data Grid – it was fun).
This entailed learning just what a Cloud Event actually was; not the theory behind it, which I’ll explain in a second, but what it was under the covers, and this is what I want to share and explain in this blog post because I personally feel that this kinda of event-driven, instantiated when needed model for writing micro-service components of a bigger system lends itself wonderfully to the on-demand and highly efficient way containerised applications can be orchestrated with Kubernetes and OpenShift.
When I started to look at it all I was seriously confuddled; the nice thing about the Cloud Event stuff is that it is abstracted to the point of ‘easy-to-use’, but I come from a background of needing to know exactly what is going on under the covers before I trust a new technology enough to use it. Yeah, I know, it’s a bad approach especially with the level of complexity of things like, say, Kubernetes, but it’s also nice to know where to look when something breaks under you.
So, the theory first – the idea behind Cloud Events is to simplify the mechanisms by which event driven applications can be triggered and routed within a Kubernetes and OpenShift cluster. In the old days (i.e. last week) a developer had to setup the queues, the connections, write their software around a specific technology etc etc. With Cloud Events it becomes superbly simple; you write your app to be driven by the arrival of a named event, the event itself is just a name and a payload, which can be anything. It’s almost the ultimate genericisation of the approach; again, in the old days, you used to choose to go down one of two routes, you *specialised* your approach (strictly defined interfaces, beans and the like) or you ‘genericised’ where your software would receive and then identify the payload, and act accordingly. Approach one leads to more, but more stable, code. Approach number two is much more agile for change.
So, long story short, the Cloud Event approach takes away all the complexity and required knowledge of the developers for the process of receiving the event and lets them just get on with the functionality. It also ties in very nicely with the knative approach, where an application is created on demand and exists for the duration of the required interaction, then goes away.
And I understood that. I just didn’t understand what a Cloud Event actually was. So I did a little digging and, with the help of the guys writing the implementation, it became clear.
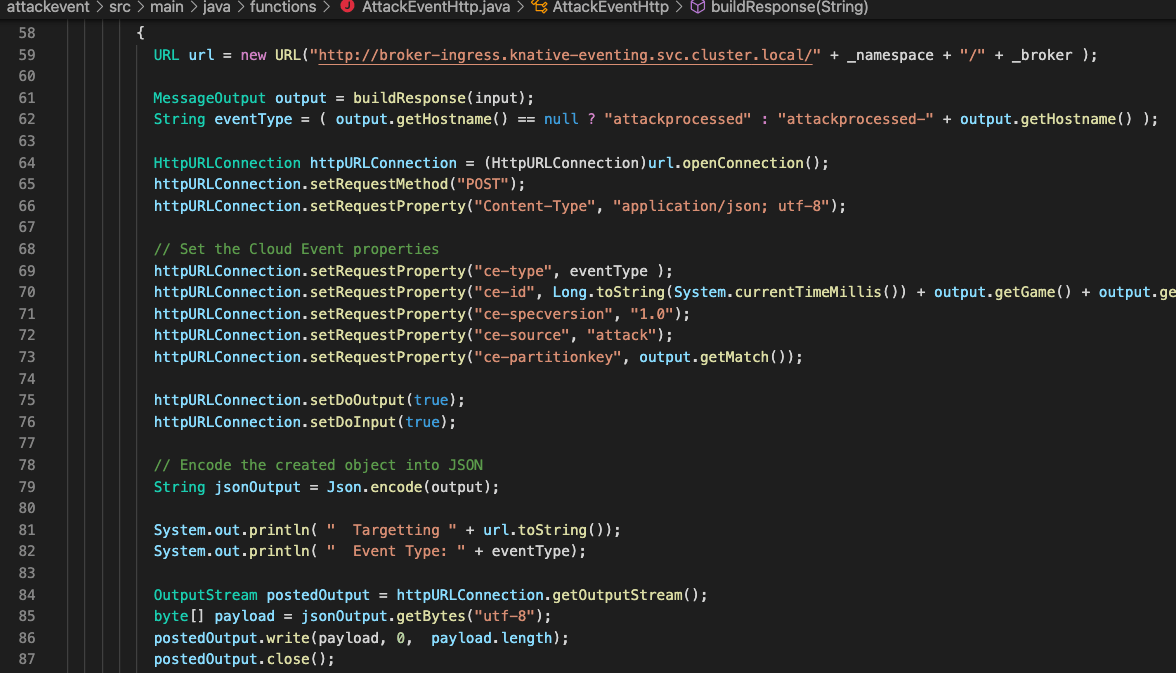
Firstly, and this was the sticky bit for me that I didn’t understand, Cloud Events are simply http posts. Nothing more complicated than that – you want to create an event, you connect to the target broker and push a post request with the appropriate (and this is the key) headers set. There are plenty of very useful APIs and the like for processing events – for example the Quarkus Funqy library, which abstract all the handling at the client side, but it was the fact that to create and send a Cloud Event you simply post to a target URL that opened my eyes on how easy it was.
A very important link I was given, which explained the ins and outs of the Cloud Event itself, was https://github.com/cloudevents/spec/blob/v1.0.1/spec.md – this is the working draft (as of May 2021) of the Cloud Event standard.
It’s very interesting to look at the mandatory header fields for the Cloud Event as they, in themselves, describe what makes Cloud Events so good and the thought process behind them – you have the id which is the unique identifier for this event; you have the source which is a context label; the combination of the id and source must be unique (within the broker) and acts as both an identifier and a context description which is neat. And you have the type which is the identifier used for routing the events (in actuality the type is related to the triggers; a trigger listens for an event of that type on a broker and forwards it to a processor as a Cloud Event).
And back to the theory – why is this such an attractive technology, to me at least? Well, it bridges two of the major problems I’ve always seemed to have when designing and implementing these systems. The idea of microservices has always appealed to me, even back when the idea didn’t exist; the concept of being able to hive off functionality into a separate unit that could be changed without having to rebuild or redesign the core of an application is very attractive, especially when the technology changes a lot. But micro-services were always a bit of a hassle to me because I didn’t want to spend my time writing 70% of boilerplate code that had nothing to do with the actual functionality (the wrappers, the beans, the config, all the bits to stand up a ten line piece of JAVA code that actually did something).
Cloud Events solves those problems and does it in spades; the abstraction to a simple format (name and payload), the simplicity of creating the events themselves (if you look at the source code in the image at the top of the blog you’ll see how easy it is to create and send a Cloud Event), it’s got the balance of configuration and code just right.
I’m intrigued to see where this technology goes and how the industry adopts it; I think they will, not only is it very powerful it’s also, and this is the most important bit, very easy to write software around. And that’s the kicker; make it easy and useful and it will get adopted big time.
