Something a little different; apologies for the quietness, been posting on the other blog site (rhuki.dev) and forgot about my own little corner of delightfulness on the World Wide Web. This post is going to be a little different as I’ve, gasp, been having some fun with AI concepts in the last couple of weeks and thought I’d share some of the work in progress.
I’m doing a talk/keynote at the AI Summit in London, in June, and wanted to have something different to demo. I’ve been working with ODH (Open Data Hub) and Spark with some customers, but wanted something a little more down-to-earth but exciting, something nobody has done before.
So I decided to see how easy it would be to model the smallest atomic components of Artificial Intelligence.
I’ve always been really interested in the *simple* bits of AI; the complexity of AI/ML solutions is always built on actually simple components, as is the human brain. All of the stuff that goes on up there is down to aggregation of billions of tiny little threshold machines – the Neurons.
I’ll take a step back; when looking at AI solutions I tend to up going one of three ways for the basic foundations – either a generational Cellular Automata model, a fluid Cellular Automata model or a Neuron based approach. In English:
With a Cellular Automata you represent the experiment/problem space with a set of autonomous objects, the cells, which can interact with each other, have behaviours based on, say, a genetic model (where new cells are created by the combination of previous cells with alterations by mutation or other Genetic algorithms). Cellular Automata are brilliant for representing and simulating population based experiments.
A Generational CA works by using a current generation of cells and calculating the next generation from the state of the current generation, then discarding the current generation. Results are often then obtained by the statistical analysis of temporal behaviours; how certain types of cell expand in number, shrink in number, change. Analysis of the start state, end state and relative populations can give some cool insights into the nature and effect of genetic modification.
A Fluid CA works slightly differently in that the transition from generation to generation isn’t done as a step; the population is randomly sampled and adjusted without considering the whole population state (in English, rather than start with a ‘current population’, process all to get the ‘next generation’ and discard the current one, you randomly select population members and apply changes there; this approach has a smaller footprint as you maintain only a single population, and because you remove the sharp step of a population->population model it can smooth out changes and produce a more natural change of state).
But onto Neurons….
I’ve alway been intrigued by the concept of the Neuron; basically an aggregation point for multiple inputs that generates a pulse, or an output, when the combination of the inputs exceeds a threshold. Yeah, that was dumbing it down to the level I understand it, but the idea of having a small processing unit that is driven, by event, and can generate an event based on the analysis of the inputs, provides a great way to build complex learning systems, especially when you can set the nature of the inputs, the behaviour of the Neuron (which can evolve) and the outputs.
In previous systems I’ve kept the Neurons simple; fire off this event if you’ve seen *all* of the input events (not at the same time), fire off an event if you have seen *all* the events at once, fire off an event of type A if you see event C and D, or an event of type B if you see event E and F, the combinations are infinite.
It gets even cooler when you start to introduce feedback loops; Neurons that fire events that end up contributing to the events that are sent to them. You can build some very complex behaviours into this kind of system. And then you can start to express the behaviour (the events in, the holistics, the events out) as strings which can then be treated as genes; throw in some periodic mutation via a genetic algorithm and you can simulate some very interesting things.
But how does this relate to development? Well, the issue with this kind of system is that in order to simulate anything of import you need a lot of Neurons; having a small number makes the results coarse, no matter how you tune and train them (think of it as trying to represent an alphabet with ten characters, there’s a lot of difference between each character and this forces a solution to collapse to a determined end ‘harder’, as in more black and white).
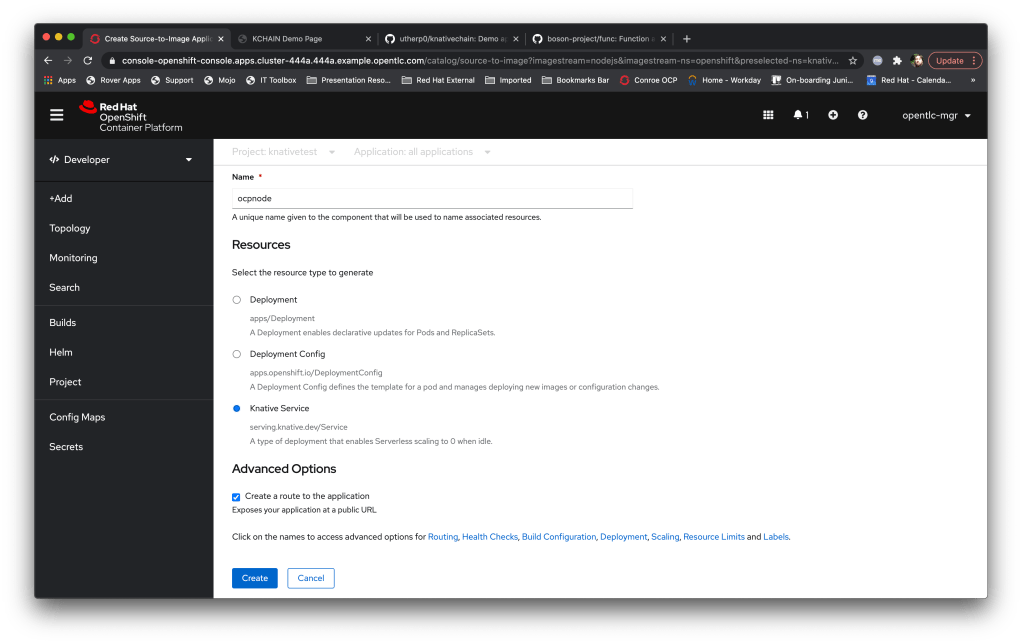
So, as a thought experiment and for demos, I’ve decided to use some of the cutting edge technologies in Kubernetes/OpenShift to build a Neural ‘play pen’ which should get around the limited compute restrictions most people have when building this kind of system.
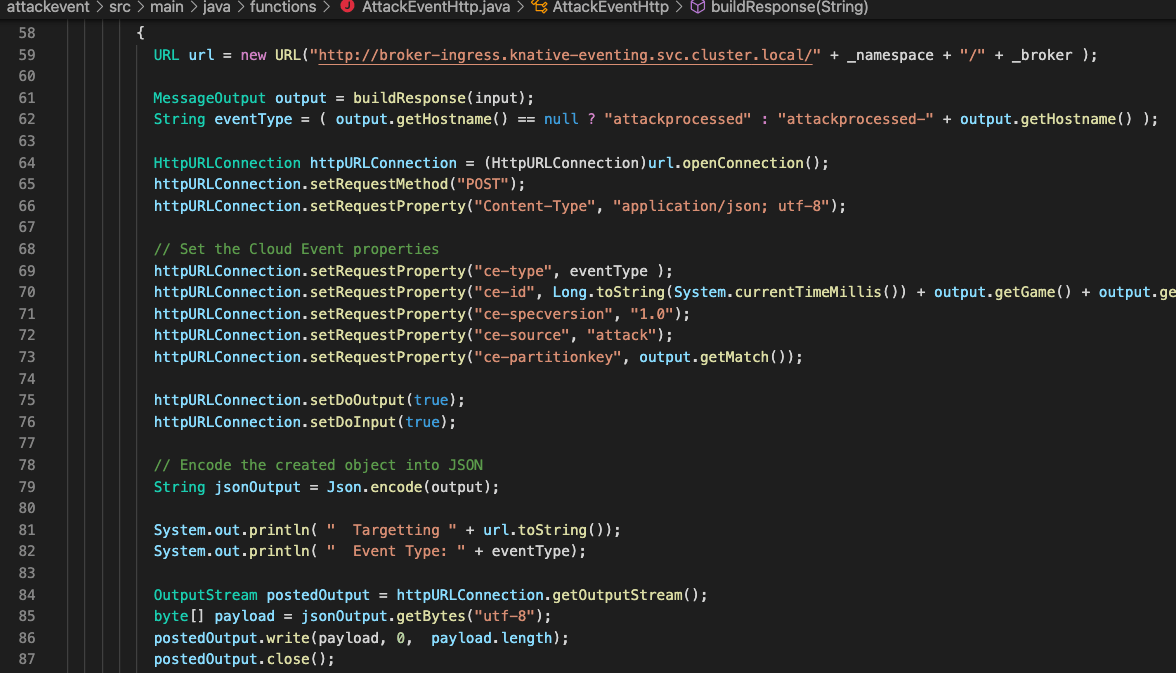
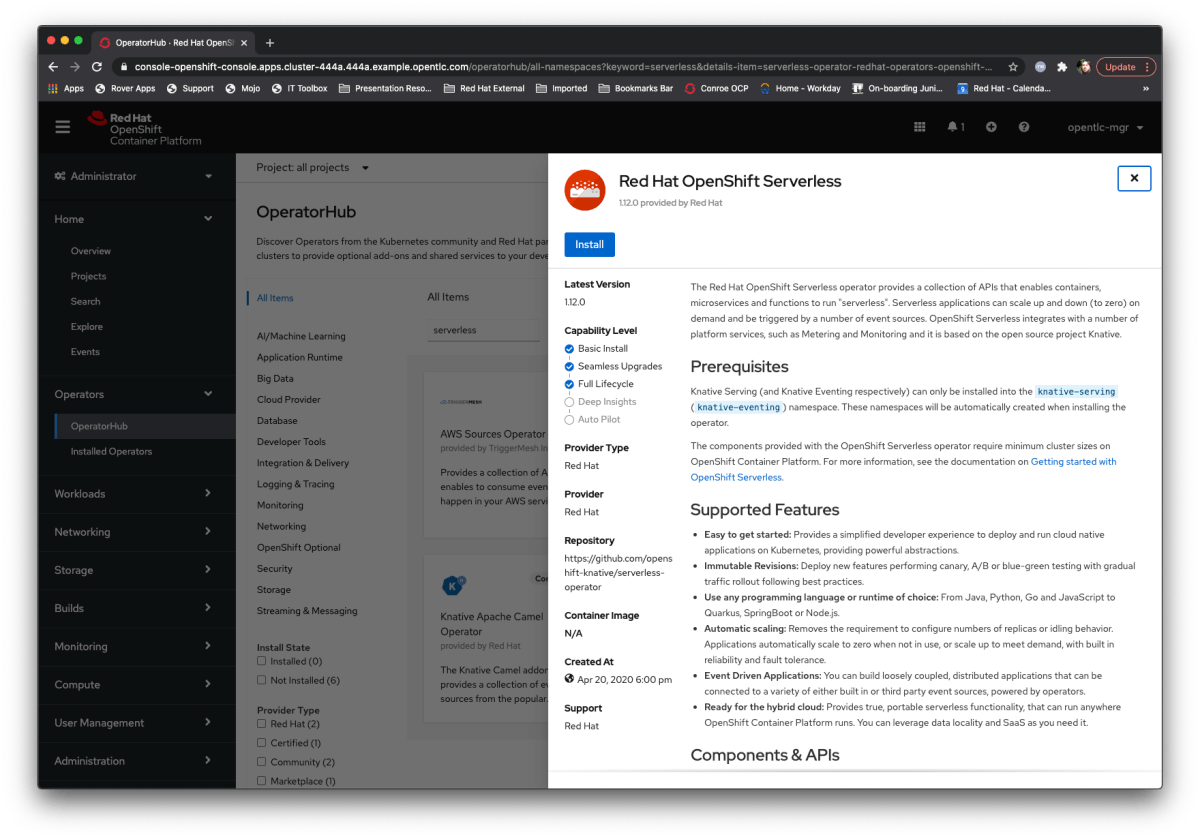
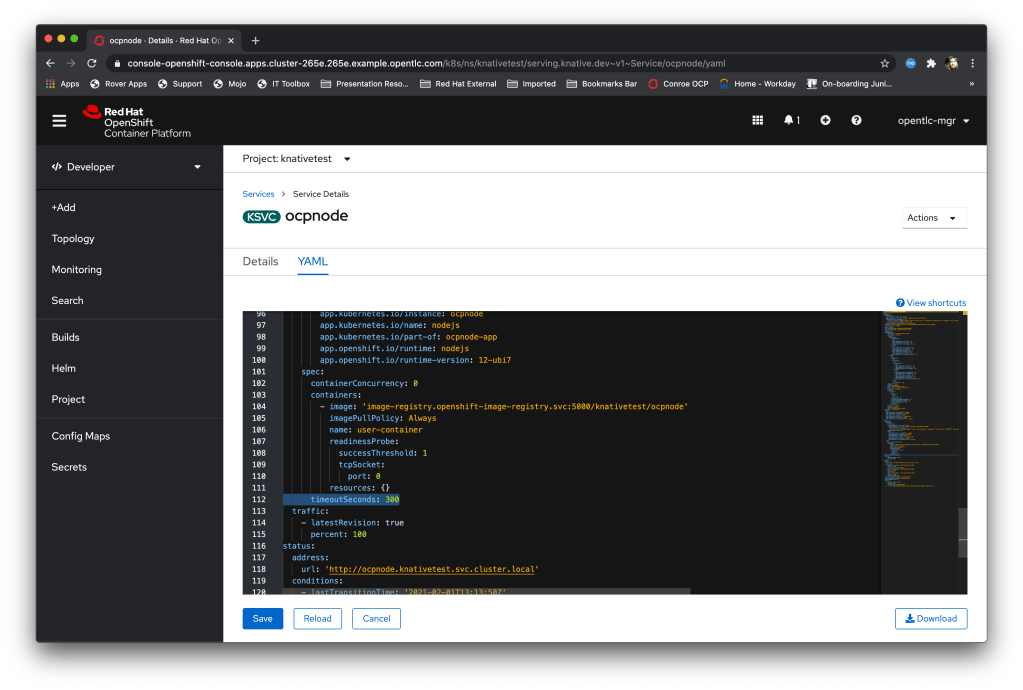
And the key component of this is the Knative serverless technology; I’ve talked about this a lot but at its simplest it’s a technology that effectively executes containers *only* when they are needed rather than standing up a Container that is waiting for traffic or an event 24/7.
My high level design is reasonably simple:
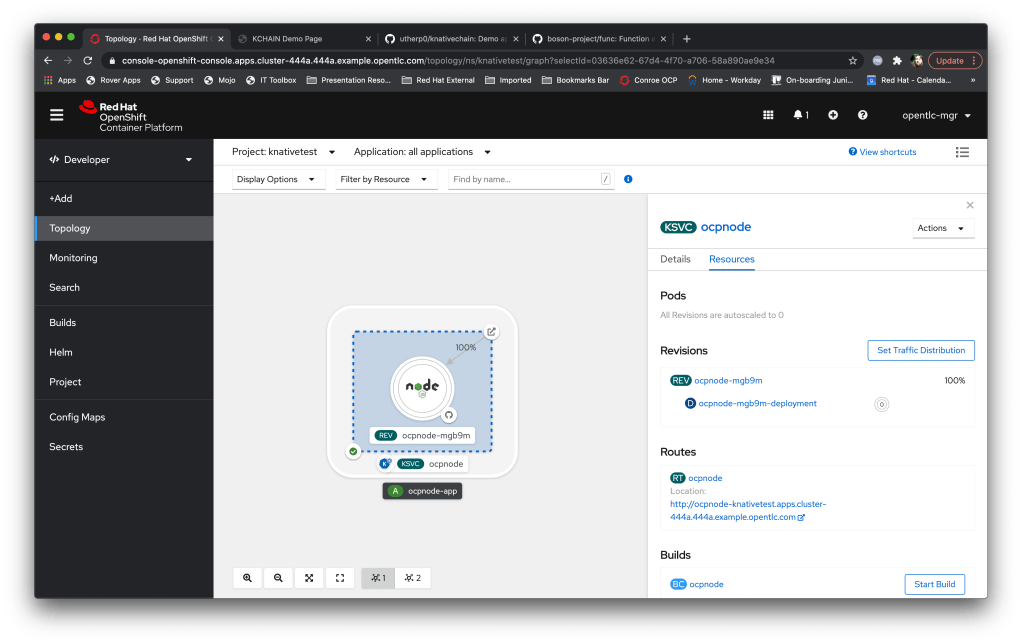
Neurons/Processors made up of knative-event driven small containers; these are created by and consume cloud events (I did a blog post a while back on those) and, as a simulation of output, throw new cloud events based on the aggregation and processing of the events they receive. Interestingly these are stateless which doesn’t make a huge amount of sense until I talk about….
Data Grid/Infinispan which is an in-memory datagrid for name/value, NoSQL data. This acts as the memory of the system; the Neurons are started by the receipt of a named cloud event, they connect to the grid and are given the data relevant to their unique instance. They then process the data and the event accordingly, push the data to the data grid, and then are timed out and decommissioned by the OpenShift cluster. The Data Grid provides the long term memory, the knative events provides the processors.
This is efficient because, in theory, I can have a huge number of inactive services. It highlights the power of Knative in that the Neurons only exist and consume resource for the duration of their processing. Also, I’m developing the initial Neurons in JAVA and compiling with Quarkus; this will allow me to build the Neurons using the Quarkus ‘native’ mode which makes for very fast startup containers, plus I love JAVA of course.
It’s early days but will provide a cool demo and allow me to do some research into the behaviour of Neural Nets using non-resident compute components, which should be very interesting.
The code for the work-in-progress stuff is available at https://github.com/utherp0/kneural – I’m calling it Kneural to keep with the Kubernetes style naming conventions.